Schedule Sync
Schedule Sync Documentation
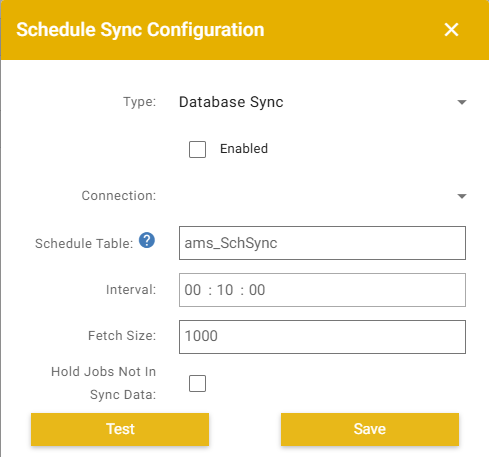
Schedule sync is the DB-pull mechanism for external control of Eclipse Pro's machine scheduling. Eclipse Pro polls a SQL table or view on a configurable interval and applies the rows.
For the conceptual model — what hold and sequencing mean, the per-row signals, and key behaviors that apply equally to the DB-pull and REST-push paths — see Schedule (Data Domains). This page documents the SQL-specific details (schema, External Connection, configuration).
If you would rather push schedule rows over HTTP than expose a SQL table, see POST /api/v1/schedule/sync. Both paths run through the same internal mapping pipeline.
This functionality serves two independent purposes:
- Managing Order Hold Status: Orders can be placed on hold or recalled from machines, even if they are currently running.
- Order Sequencing: The order of execution for jobs on a machine can be externally defined.
SQL Schema
| Field Name | Type | Size | Required | Description |
|---|---|---|---|---|
| order_ | varchar | 20 | Yes | Unique order identifier |
| material | varchar | 20 | Yes | Material associated with the order |
| pcode | varchar | 20 | Yes | Production code |
| onhold | tinyint | - | No | Indicates if the order is on hold (1 = Yes, 0 = No) |
| machinenum | int | - | Conditional | Machine number assigned to the order. Required when Sync Machine Sequence is enabled. |
| sequence | int | - | Conditional | Sequence number determining execution order. Required as a column when Sync Machine Sequence is enabled, though individual rows may leave it null (see Order Sequencing). |
| sqlplant | varchar | 3 | No | Plant identifier |
Creating the schedule sync table (SQL Server)
The following script creates a new schedule sync table with every supported column. Replace [ScheduleSync] with whatever name you'd like to point Eclipse at.
CREATE TABLE [dbo].[ScheduleSync] (
order_ VARCHAR(20) NOT NULL,
material VARCHAR(20) NOT NULL,
pcode VARCHAR(20) NOT NULL,
onhold TINYINT NULL,
machinenum INT NULL,
sequence INT NULL,
sqlplant VARCHAR(3) NULL,
CONSTRAINT PK_ScheduleSync PRIMARY KEY (order_, material, pcode)
);
The primary key on (order_, material, pcode) matches how Eclipse identifies jobs — the same triple uniquely identifies a job in Eclipse. Drop the constraint if your ERP cannot guarantee uniqueness on that combination.
Adding machinenum and sequence to an existing table (SQL Server)
If your existing schedule sync table predates the Sync Machine Sequence feature, add the two columns before enabling it. Replace [YourScheduleSyncTable] with your actual table or view name.
ALTER TABLE [dbo].[YourScheduleSyncTable]
ADD machinenum INT NULL,
sequence INT NULL;
If you are syncing from a view rather than a base table, add the columns to the underlying base table first and then update the view's SELECT list to include them.
Setting Order Hold Status
This feature allows an external system (e.g., ERP) to control the hold status of orders without relying on integration middleware to detect and apply changes.
- Orders Not Yet Sent to a Machine: Placing an order on hold prevents it from being assigned to a machine. A scheduled order will remain in the schedule but will be skipped.
- Orders Already at a Machine: Setting an order on hold recalls it from the machine. If the order is currently running, the machine will be halted before recalling the order.
Hold Jobs Not In Sync Data
This option places all existing orders on hold if they are absent from the source data. If an order is deleted from the ERP, this setting ensures that it is held. While this behavior is often desirable, manually entered test orders will also be continuously held.
Order Sequencing
Schedule Sync can drive each machine's queue from the source table using the machinenum and sequence columns. This is opt-in — enable Sync Machine Sequence on the config to turn it on. When off, the columns are ignored and only hold processing applies.
The sequence value is a sorting key within a machine, not a fixed position. Values do not need to be contiguous, and you can leave gaps between numbers to make future inserts easier.
How rows are interpreted
For every row matched to a job in Eclipse, the columns are interpreted as follows:
machinenum | sequence | Effect |
|---|---|---|
| Positive integer | Positive integer | Place the job on that machine at that relative position. |
| Positive integer | Null / empty | Place the job on that machine, appended to the end of the machine's sequence (after any explicitly sequenced rows for that machine). |
0 | (any) | Explicit unschedule. The job is removed from whichever machine it is currently on — machinenum and sequence are cleared and its status returns to unscheduled. Any sequence value on the same row is ignored. |
| Null / empty | (none) | The row carries no machine assignment. If the job is currently scheduled on a machine, the orphan rule (below) applies. |
| Null / empty | Non-empty | Invalid combination. The row is rejected with a failure note and the job's schedule position is not changed. |
Key behaviors
- Per-machine atomicity — Each machine's new sequence is applied as a single batched operation. Other machines proceed independently if one is rejected.
- Running jobs are untouchable — A job that is currently on the controller (running, sending, or being recalled) keeps its current machine and position. If the source table requests a move for such a job, that row is rejected with a failure note. The job will not be displaced mid-run.
- Cross-machine moves are supported — If a job is currently queued on machine A and the source row assigns it to machine B, it is removed from A's queue and added to B's queue at the requested position.
- Orphans are held and recalled — A job currently scheduled on machine M that does not appear in the source data for M (and is not moving to another machine in the same sync) is placed on hold and recalled from M. This is the same mechanism as
Hold Jobs Not In Sync Data, scoped per machine. - Hold + sequence both apply — If a row carries
onhold = 1together with amachinenumvalue, the job is placed at the requested position and marked on hold. ERP intent stays visible — un-hold the job later by settingonhold = 0on the same row. - Duplicate sequence numbers are tie-broken — When multiple rows on the same machine share a
sequencevalue, ties are broken deterministically byOrdId. This lets the ERP intentionally group several jobs at the same sequence to mean "these go together; the exact order within the group doesn't matter." - Same order listed twice rejects the machine — If the same
(order_, material, pcode)appears more than once for a single machine, that one machine's sequence is left untouched and failure notes are recorded. Other machines proceed normally. - Order of operations — Within a single sync run, hold/recall actions are applied first to clear the affected machines, then the new sequences are written. This avoids transient collisions.
Limitations
- Job must exist in Eclipse — Source rows are matched to existing jobs by the
(order_, material, pcode)triple. Rows that don't match any job are rejected with a failure note; they do not create new jobs. - Sequence column is required when the feature is enabled — When Sync Machine Sequence is enabled, the connection test verifies that both
machinenumandsequencecolumns exist on the table or view. Individual rows may still leave the values null, but the columns themselves must be present.
Configuration